

[画像1: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-2726c51a5a584c82393ba26387b817ec-1920x1080.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
大規模言語モデル(LLM)の社会実装を進める株式会社ELYZA(代表取締役:曽根岡侑也、以下当社)は、内閣府が設置した「戦略的イノベーション創造プログラム(SIP:エスアイピー)」(※1)が公募したSIP第3期補正予算「統合型ヘルスケアシステムの構築における生成AIの活用」(※2)のうち、テーマ1「医療LLM基盤の研究開発・実装」における研究開発課題「日本語版医療LLMの開発ならびに臨床現場における社会実装検証」にて、医療領域における国産の特化LLM基盤の開発を担いました。本研究において構築した日本語版医療LLM「ELYZA-LLM-Med」シリーズは、総合点で国内最高性能を達成、現場の医療タスクにおいてはグローバルトップ水準を超える精度を実現しています。また、今回の特化LLM基盤開発において使用し、有効性を検証したアプローチは、特定の領域における特化モデル開発において汎用性の高いアプローチであり、多くの領域で横展開が可能と考えております。
研究の目的や技術的な成果の詳細については、当社テックブログを御覧ください。
- [Part1] 日本医療 x LLM: ユースケース応用の基盤となる日本語版汎用医療LLMの開発
- [Part2] 日本医療 x LLM: 電子カルテ標準化のための情報変換タスク
- [Part3] 日本医療 x LLM: 診療報酬明細書の作成を補助する情報推薦タスク
ELYZAでは引き続き、AIエージェント等を含む最先端の研究開発に取り組んでいくとともに、その研究成果を可能な限り公開・提供することを通じて、国内におけるLLMの社会実装の推進、並びに自然言語処理技術の発展を支援してまいります。
なお、本プロジェクトのメンバーとして、さくらインターネット株式会社の組織内研究所であるさくらインターネット研究所が研究代表として共同研究機関を統括し、株式会社ELYZA、東京大学松尾・岩澤研究室が医療特化型LLMの開発を、株式会社ABEJAがデータの調達や加工・LLMシステムの開発を担当しました。また、個人情報を扱う場面では、セキュアな計算基盤環境を保有する理化学研究所にて検証を行いました。今回焦点を当てるユースケース群については、国際医療福祉大学や学校法人藤田学園 藤田医科大学等の医療機関と連携しながら、データの取得や加工を行いました。
※1:https://www8.cao.go.jp/cstp/gaiyo/sip/
※2:https://sip3.jihs.go.jp/index.html
開発したモデル群
本研究では、1. 各ユースケースの基盤となる日本語版汎用医療LLMの開発と、2. 各ユースケースを解くための日本語版汎用医療LLMの適合(【ユースケース1-電子カルテ標準化のための情報変換】【ユースケース2-レセプト(診療報酬明細書)の確認修正内容の提案】)に向けたモデル開発を行いました。最終的な開発モデル群は以下になります。なお、各ユースケースの具体内容や詳細な評価軸については、当社テックブログを御覧ください。
0.ELYZA-LLM-Med
今回当社が開発した日本語版医療特化LLMシリーズの総称です。
1.ELYZA-Med-Base-1.0-Qwen2.5-72B
各ユースケースの基盤となる日本語版汎用医療LLMです。海外製のオープンなモデルである「Qwen2.5-72B-Instruct」をベースに、複数の医療関連コーパスを用いた継続事前学習を行ったモデルです。
2.ELYZA-Med-Instruct-1.0-Qwen2.5-72B (UC1)
「ELYZA-Med-Base-1.0-Qwen2.5-72B」に追加の事後学習(SFT)を行い、【ユースケース1-電子カルテ標準化のための情報変換】に適合するよう調整を施したモデルです。
3.ELYZA-Med-Instruct-1.0-Qwen2.5-72B (UC2)
「ELYZA-Med-Base-1.0-Qwen2.5-72B」に追加の事後学習(SFT)を行い、【ユースケース2-レセプト(診療報酬明細書)の確認修正内容の提案】に適合するよう調整を施したモデルです。
基盤モデルは、国内最高性能を達成
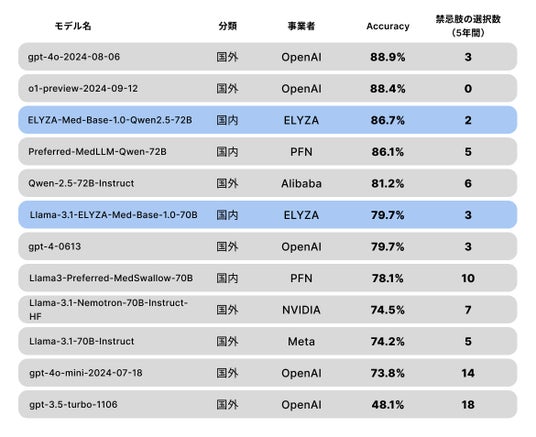
医師国家試験ベンチマーク「IgakuQA」(※3)において、「ELYZA-Med-Base-1.0-Qwen2.5-72B」は国内最高性能を達成しました。※3:https://github.com/jungokasai/IgakuQA
[画像2: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-588248baca871d6929eb771fb91abb0d-1169x954.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
表1:継続事前学習済モデルと他モデルのIgakuQAの精度・禁忌肢数比較
現場の医療タスクにおいてはグローバルトップ水準超え
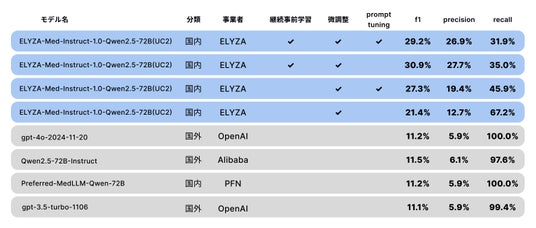
【ユースケース1-電子カルテ標準化のための情報変換】では、「ELYZA-Med-Instruct-1.0-Qwen2.5-72B (UC1)」はOpenAI社の「o1(2024-12-17)」を超える性能を達成しました。[画像3: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-92aefaa63d11ccc2d223d9796d46c7f8-1643x954.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
表2:UC1(電子カルテ標準化のための情報変換)の精度比較
【ユースケース2-レセプト(診療報酬明細書)の確認修正内容の提案】では、「修正要否の精度」「コメントの質」の双方において、「ELYZA-Med-Instruct-1.0-Qwen2.5-72B (UC2)」はOpenAI社の「gpt-4o(2024-11-20)」を超える性能を達成しました。
[画像4: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-95ce63a29942ad93c706e4df8bb9559d-1561x663.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
表3:UC2(レセプト修正)における、修正要否判定の精度比較
[画像5: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-7c2df0cfd7750b994329d3d6859c205e-1702x663.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
表4:UC2(レセプト修正)における、コメントの質の比較
本研究で使用したアプローチ
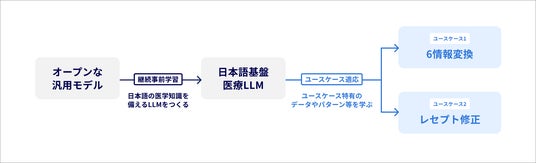
[画像6: https://prcdn.freetls.fastly.net/release_image/47565/61/47565-61-de6cff34a50007c361ddb20962c796a4-1920x583.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]図1:アプローチ図
開発にあたっては、今後の医療DXを牽引していく技術基盤として、より多くのユースケースに対応すべく、まず根幹となる日本語版汎用医療LLMを開発し、それをベースに各ユースケースへ適合させるアプローチを取りました。(図1)
単一のユースケースに閉じた場合でも、医療という専門的なドメインにおいて要件定義やデータ整備を行うことは容易ではありません。そのため、ユースケース間で開発の足並みが揃わない可能性を考慮し、共通部分をあらかじめ学習させることとしました。
また、オープンなモデルに関する国内外の開発状況を踏まえると、モデルの基本性能は今後も頻繁に改善されていくと考えられます。そこで、継続事前学習を採用し、今後も高性能なモデルを効率的に作成し続けることを可能にしました。
本研究成果の意義
今回の特化LLM基盤開発において使用し、有効性を検証できたアプローチは、特定の領域における特化モデル開発において汎用性の高いアプローチであり、多くの領域で横展開が可能と考えております。昨今、医療に限らない多くの領域で、特化エージェントの構築を目指す機運が高まっておりますが、特化領域かつ具体タスクを前提とした特化エージェントの構築においては、プロプライエタリモデルを活用するのではなく、LLM開発の技術力を具備したAIカンパニーと並走しながら内製で特化モデルを作り上げるという選択肢も候補に入ることを、本研究で証明できたのではと考えております。
なお、本リリースで紹介した成果は、「戦略的イノベーション創造プログラム (SIP)」「統合型ヘルスケアシステムの構築 JPJ012425」 の補助により得られたものです。
今後の展望
本研究成果等も踏まえながら、当社は今後、特定領域に特化したLLMソリューションを順次展開していく予定です。一方で、特化領域でのLLMソリューション構築には、該当領域に関する大量のデータが必要となります。当社ELYZAは社会実装に向けたデータパートナー・PoCパートナーを随時募集しております。特化領域でのデータを保有する、LLM活用にご興味のある企業様はぜひお声がけください。
株式会社ELYZA 会社概要
株式会社ELYZAは「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形で大規模言語モデルの導入実装を推進します。社名 :株式会社ELYZA
所在地 :〒113-0033 東京都文京区本郷3-15-9 SWTビル 6F
代表者 :代表取締役 曽根岡 侑也
設立 :2018年9月4日
URL :https://elyza.ai/
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}