
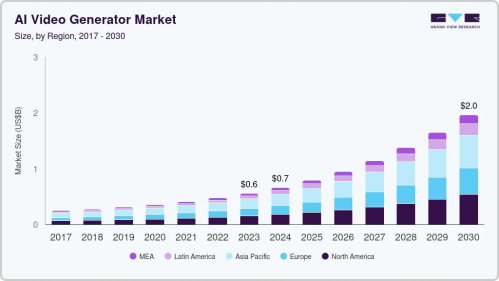
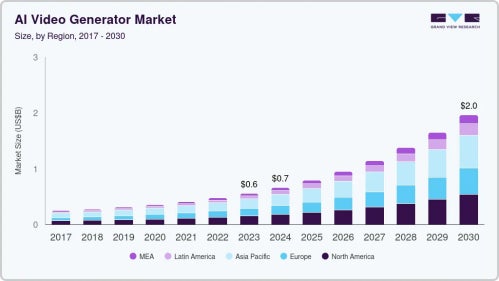
近年、AI動画生成技術は急速に普及しており、企業やクリエイターの動画制作環境に大きな変革をもたらしています。市場調査によると、2023年のグローバルAI動画生成器市場規模は約5.549億米ドルと推定され、2024年から2030年にかけて年平均成長率(CAGR)19.9%で拡大し、2030年には約19.5924億米ドルに達すると予測されています。
[画像: https://prcdn.freetls.fastly.net/release_image/173897/5/173897-5-27d0a70e599ca60d69d03611c5bff78f-499x281.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
データ出典:Grand View Research
特に2025年以降、Veo 3(Google)や Sora 2(OpenAI)をはじめとする新世代モデルの登場により、AI動画生成は用途や性能特性の多様化が一層進んでいます。
一方で、各モデルの性能差や得意分野を横断的かつ客観的に比較できる情報は依然として限られており、企業やクリエイターにとって「どのモデルを、どの目的で選択すべきか」を判断することは容易ではありません。市場の拡大とともに、実運用を前提とした評価指標や検証データの重要性が高まっています。
こうした背景を受け、LitMedia が提供するAI動画生成プロダクト「LitVideo」は、主要なAI動画生成モデル10種以上を対象とした技術検証レポートを公開しました。本検証では、すべてのモデルを統一条件下で比較し、生成品質、指示理解力、音声と映像の同期精度、物理表現の傾向などを多角的に分析しています。本稿では、その検証結果をもとに、AI動画生成市場の現状と各モデルの技術的特性を整理します。
なお、LitMedia はAI動画生成、AI画像生成、AI音楽制作などを包括的に提供するAIテクノロジー企業が運営する総合クリエイティブプラットフォームです。複数の最先端生成モデルを統合し、誰でもブラウザ上で高品質なコンテンツ制作を行える環境を構築しています。現在は、最新世代モデル「Sora 2」を期間限定で無料体験 できるキャンペーンも実施しています。
次世代・高品質志向モデルを中心としたAI動画生成の分類動向
本検証では、生成品質や音声統合の完成度といった技術指標に加え、実運用における用途適性の違いが複数のモデル間で明確に確認されました。これを踏まえ、LitMedia が公開した測評レポートでは、検証対象となったAI動画生成モデルを、性能特性および想定ユースケースの観点から3つのカテゴリに整理しています。
第一のカテゴリは、映像と音声を一体で生成し、高度な物理再現や演出表現を志向する最上位モデル群です。
本グループには、Google が開発した Veo 3 と、OpenAI による Sora 2 が含まれ、映画的表現や物語性の高い動画生成を想定した設計が共通の特徴とされています。音声生成やリップシンクを含む統合的な表現力は、現行市場における技術的上限に近い位置づけといえます。
第二のカテゴリは、映像制御精度やスタイル一貫性、制作効率を重視した高性能モデル群です。
ここには、Hailuo 2.3(MiniMax)、Seedance(ByteDance)、および Wan 2.2 が含まれます。
これらのモデルは、必ずしも音声生成を主軸とせず、量産性、映像の安定性、運動表現や構図制御といった要素を重視する設計が特徴です。広告素材、ブランド動画、反復的な制作フローなど、実務用途での効率性を意識した技術的方向性が確認されました。
第三のカテゴリは、即時生成性と操作性を重視し、配信・プロモーション用途に適応したモデル群です。
本グループには、PixVerse および Vidu が該当します。
短時間での生成、直感的な操作性、縦型・正方形など多様な配信フォーマットへの対応力が重視されており、SNSコンテンツや情報流通型動画の制作を前提とした設計思想が見られます。特に Vidu は、画像参照を活用したキャラクター一貫性や表情表現といった点で独自の方向性を示しています。
このような分類は、AI動画生成市場が「単一指標による性能競争」から、用途別に最適化されたモデルを選択・併用するフェーズへ移行していることを示すものです。
以下では、各カテゴリごとに代表的なモデルの技術的特徴と、同一条件下での検証結果から確認された傾向を整理します。
音声統合と物理再現を軸に進化する最上位生成モデルVeo 3(Google)
Google が2025年5月に発表した Veo 3 は、単一の指示から映像と音声を同時に生成できる点で、従来のAI動画生成技術とは一線を画しています。環境音、効果音、人物の対話、背景音楽までを含めて自動生成できることが確認されており、特に唇の動きと音声を同期させるリップシンク機能は、人物会話シーンの自然さを大きく向上させています。
検証では、自然光の表現や空間全体の雰囲気構築において高い完成度が確認され、現実世界の物理挙動に対する理解の深さが映像全体の説得力につながっていることが明らかになりました。一方で、指示内容が極めて詳細かつ複雑な場合には、意図の解釈が硬直化し、シーンの一貫性や物理的整合性が低下するケースも確認されています。
同一プロンプトによる生成結果の比較について
[動画1: https://www.youtube.com/watch?v=WiA8ZMek1sM ]
Sora 2(OpenAI)
OpenAI が公開した Sora 2 は、動画を生成するモデルとして、指示理解力と物理挙動の再現性を大きく進化させたモデルです。
検証では、人物の動作や表情、音声の補完において高い整合性が確認され、シーンに応じた自然な会話や効果音が自動的に生成される傾向が見られました。
また、映画風からアニメ調、写実表現まで幅広いスタイルに対応できる点も特徴で、物語性のある短編動画や広告用途への適性が高いモデルといえます。
一方で、映像の美術的完成度や画面演出においては、Veo 3 と比較するとやや簡素な傾向が見られ、設計思想の違いが明確に表れています。
同一プロンプトによる生成結果の比較について
[動画2: https://www.youtube.com/watch?v=NCfQLsWri_E ]
本検証では、Veo 3 と Sora 2 に対して同一のテキストプロンプトを入力し、生成された動画を比較しています。
両モデルの生成結果を通じて、「映像美と演出を重視する設計」と「指示理解と物理挙動の安定性を重視する設計」という、最上位モデル間における明確な方向性の違いが確認されました。
詳細な生成結果および動画比較については、LitMedia が公開している検証レポートおよび比較動画をご参照ください。
実用指向AI動画モデル群の検証概要Hailuo 2.3(MiniMax)
高スループット型・量産向けAI動画生成モデルHailuo 2.3 は、MiniMax が提供する動画生成モデルで、単価あたりの生成量と処理速度を重視した設計が特徴です。従来モデル(Hailuo 02)からの効率改善版として位置づけられ、価格を維持したまま出力品質を向上させています。
検証では、同一プロンプトに対して写実的な再現や音声生成には制約が確認されましたが、一方で画面構成や雰囲気表現の安定性は高く、スタイルが一定に保たれる傾向が見られました。
本モデルは、製品ループ映像、簡易Bロール、短尺の定型フォーマットなど、反復性の高い制作工程において、コストとスループットを優先する用途に適したモデルと位置づけられます。
同一プロンプトによる生成結果の比較について
[動画3: https://www.youtube.com/watch?v=zP6HdqbYV4Q ]
Seedance(ByteDance)
スタイル適応力と一貫性を重視したブランド・広告向けモデル
Seedance は、ByteDance が開発・運用する画像・動画生成モデル群で、参照スタイルの適用と映像一貫性に強みを持つ設計が特徴です。
イラスト、絵画、アニメ調などの美術的スタイルを動画に反映しつつ、被写体の動きや構図を安定して保持できる点が評価されています。
検証では、Seedance 1.5 において映像と音声の同期生成が確認され、背景音・環境音・簡易的な音声要素が自然に統合される傾向が見られました。
この特性から、Seedance はブランドキャンペーン、広告用動画、スタイル統一が求められる短編映像に適したモデルとして位置づけられます。
同一プロンプトによる生成結果の比較について
[動画4: https://www.youtube.com/watch?v=fZxl1dl8Se8 ]
Wan 2.6
運動表現とセマンティック制御を軸に進化した高精度モデル
Wan 2.6 は、MoE(混合専門家)アーキテクチャを採用し、大きな動きや複雑なモーションの再現性、ならびに複数被写体を含むシーンの意味理解精度を高めた最新世代の動画生成モデルです。光影・構図・色彩といった映画的要素の制御にも対応しています。
本検証では、新たに音声生成とリップシンク(口形同期)が可能となり、動作と発話を同時に生成できる点が技術的な進展として確認されました。一方で、画面の自然さや人物の質感・表情表現にはまだ不安定さが残り、ライティングや動きのつながりに人工的な印象が生じるケースも見られます。
同一プロンプトによる生成結果の比較について
[動画5: https://www.youtube.com/watch?v=8ZnsTJG5t9I ]
本カテゴリのモデル群は、AI動画生成が「最高品質の一点生成」から、
用途別・工程別に最適化された制作インフラへと進化していることを示しています。
LitMediaが提供する LitVideoでは、今回の検証結果を踏まえ、生成品質、コスト、スピード、音声対応の有無などを軸に、用途別に最適なモデルを選択できる環境整備を今後進めていく予定です。
同一プロンプト下での生成動画比較は、各モデルの技術的特性を理解するうえで有効な指標となっており、詳細はレポート本文および比較動画をご参照ください。
表現力と即時性を重視した次世代AI動画生成モデル群
映画的な高精度再現を追求する最上位モデルとは異なり、近年のAI動画生成市場では、表現力・即時性・制作フローへの組み込みやすさを重視したモデル群が存在感を高めています。Vidu(ShengShu Technology × 清華大学)
Vidu は ShengShu Technology が清華大学と共同開発したマルチモーダルAI動画生成プラットフォームであり、「映像の生成」ではなく「演技や表現の再現」に重点を置いた設計思想が特徴です。U-ViT アーキテクチャに基づく拡散モデルを採用し、最大16秒・1080pの動画を単一生成で扱える点は、長尺化が進むAI動画分野において重要な技術的進展といえます。
2025年初頭に公開された Vidu Q1 では、シーン全体を一貫して制御する生成パイプラインを導入し、続く Vidu Q2 では、キャラクターの微細な表情変化やカメラワークの再現が強化されました。一方、今回の検証では、テキストのみを入力とする文生動画において、解像感や対話音声の再現に課題が確認されています。
その反面、画像から動画を生成するワークフローでは高い安定性を示しており、複数の参照画像を用いた人物の一貫性や感情表現の保持に優れています。Vidu は、特にアニメーションやスタイル化表現において、キャラクター忠実度を重視する用途向けのモデルとして位置づけられます。
同一プロンプトによる生成結果の比較について
[動画6: https://www.youtube.com/watch?v=PPUrKvLC14s ]
PixVerse
PixVerse は、生成速度と扱いやすさを軸に急成長しているAI動画生成ツールの一つです。シンプルなテキスト入力から短時間で映像を生成できる点に加え、無料プランであっても透かしなし・HD画質での出力が可能な設計は、市場において明確な差別化要因となっています。
検証では、ライティングや被写界深度、人物の動きといった映像表現の基礎品質が安定しており、短尺動画や広告用ビジュアルとして実用的な水準が確認されました。また、顔認識を用いたエフェクト適用により、人物の同一性を保ったまま演出を加えられる点は、マーケティング用途との親和性が高い特徴です。
一方で、PixVerse は音声や音楽のネイティブ生成には対応しておらず、動画は無音で出力されます。今回の検証でも、音声要素は LitVideo 側の機能によって補完されており、映像生成に特化したモデルであることが明確になりました。
同一プロンプトによる生成結果の比較について
[動画7: https://www.youtube.com/watch?v=rmjALNgOXBg ]
本検証結果は、AI動画生成モデルを一律に評価するのではなく、目的や制作工程に応じて選択・組み合わせる時代に入ったことを示唆しています。
まとめ|用途別に進化するAI動画生成モデルと今後の展望
本検証を通じて、AI動画生成モデルは単一の性能指標で評価される段階を超え、生成品質・音声統合・表現力・制作効率・配信適性といった用途別特性に応じて選択されるフェーズへ移行していることが明らかになりました。最上位モデルによる映画的表現から、量産性や即時性を重視した実用型モデルまで、各技術は異なる制作現場のニーズに応える形で進化を続けています。
LitMediaでは、こうした市場動向と検証結果を踏まえ、AI動画生成ツール「LitVideo」を通じて、用途別に最適なAI動画モデルを選択・活用できる環境整備を今後さらに推進していく予定です。
複数モデルの特性を横断的に比較・検証することで、企業やクリエイターが目的に応じた最適な生成手法を選べる基盤の構築を目指します。
LitMediaは今後も、AI動画生成技術の動向を継続的に検証・分析し、企業やクリエイターが安心して活用できる実践的な生成環境の構築に取り組んでまいります。
今すぐ LitVideo を無料で試す



















{kind=link}