

[画像1: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-23df8930fe0e147648dfaf4661e019a1-1200x630.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之、以下「Visual Bank」)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』において、『日本語・2話者・ビジネス会話の音声コーパスと発話内容のテキストデータセット』の提供を開始しました。
本データセットは、日本語の自然な2話者対話を数百時間規模で収録し、発話テキスト・話者区分・タイムスタンプを付与した音声認識(ASR)・会話理解・要約生成AI向け学習データです。
研究・商業利用を問わず、日本語音声コーパスの高精度化やCX解析AI、会話型LLMの学習データとして活用可能です。
*Qlean Dataset(キュリンデータセット):https://qleandataset.visual-bank.co.jp/
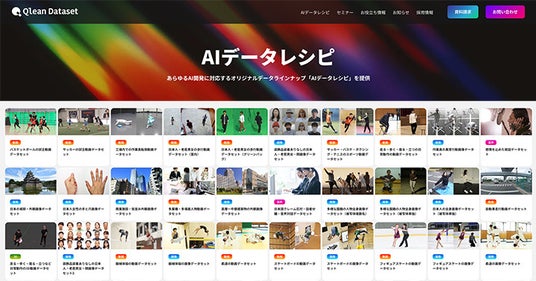
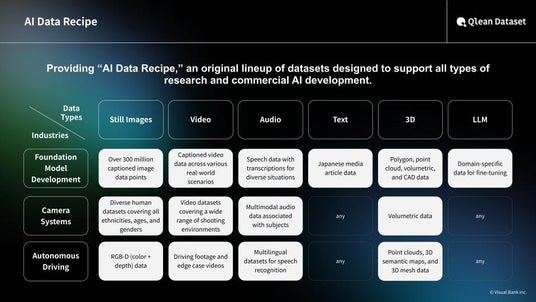
『Qlean Dateset(キュリンデータセット)』の「AIデータレシピ」について
『AIデータレシピ』は、『Qlean Dataset』における商用利用可能なオリジナルデータラインナップです。
用途や精度・納期に応じて、すぐに使えるデータ素材を柔軟に組み合わせられる構成が特長で、一部アノテーション済み/未付与のデータや、個別要件に応じた構成変更・拡張にも対応可能です。
また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社とのパートナーシップ、国内外のネットワーク、新規収録などを通じて、ラインナップの拡充を進めています。
これにより、AI開発現場でのデータ収集・整備にかかる負荷を大幅に軽減し、開発の加速に貢献します。
[画像2: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-7b5b1345f0143754333820fff134b464-720x378.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像3: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-cd60fa9ecd269b2c916a32c90bdea2d9-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像4: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-2a6364fd03da0259d366ea958a46d57f-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像5: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-2087ebe047d45ed27f17e66857058c6e-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
今回提供を開始する「日本語・2話者・ビジネス会話の音声コーパスと発話内容のテキストデータセット」の概要
- データ種別: 音声、テキスト
- 被写体属性:日本人男女
- データ形式:音声データ:wav、テキストデータ:txt
- 備考
[収録時間] 数百時間
[対象のシーン] 商談、SaaS問い合わせ対応、架電対応 など
[テキスト書き起こし構成] 行番号、開始時間、終了時間、話者区分、発話内容
- サンプル詳細URL:https://qleandataset.visual-bank.co.jp/lineup/pn-013
[画像6: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-2803a9dce0745a7daaea8c934302c09e-1200x630.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
※こちらはシチュエーションイメージです。
「日本語・2話者・ビジネス会話の音声コーパスと発話内容のテキストデータセット」のユースケースイメージ
- 音声認識・話者分離AIの高精度化
オンライン会議や対面会話を多環境で収録。ノイズ耐性や被り発話にも対応しており、音声認識(ASR)や話者分離モデルの性能向上、リアルタイム議事録AIの開発にご利用いただけます。
- 会話理解・要約生成AIのトレーニング
開始・終了時刻や話者区分が付与された精密な書き起こし構造により、長時間会話の要点抽出・要約AI、次発話予測型の生成AIモデルの学習データとして最適です。
- 顧客体験(CX)・感情音声認識AIの開発
声のトーンや応答の間など感情的ニュアンスを含むため、顧客満足度・対応品質を解析するCX向けAIモデルやコールセンター自動評価AIの開発に活用できます。
- 商談解析・セールスインテリジェンスAIの研究
営業や職業面談などの実務対話を網羅しており、発話パターンや傾聴姿勢などを数値化する商談解析AI・セールスコーチングAIの基礎データとして利用できます。
- コンタクトセンター自動応対AI・FAQ生成AIの構築
カスタマーサポートや問い合わせ対応の実音声が含まれており、FAQ自動生成AIや音声応答型チャットボットの会話チューニングデータとしてご活用いただけます。
- 音声UX・会話体験デザインの研究開発
自然な会話テンポや相槌表現を含むリアルな音声データは、AIアシスタント・スマートスピーカーなど音声UI/UX設計の自然対話学習に最適です。
- 感情変化検知AIによる“体験の質”評価
発話ピッチ・間合い・テンション変化を解析することで、会話中の心理状態変化や満足度推定AIの研究に利用できます。CX定量化・接客トレーニングAIにも応用可能です。
- 日本語LLM/マルチモーダル生成AIの会話学習
音声とテキストのペア構造により、マルチモーダルLLMの音声理解や日本語対話生成の強化に活用できます。自然な日本語会話を再現する生成AIやボイスチャットLLMの研究用途にも適しています。
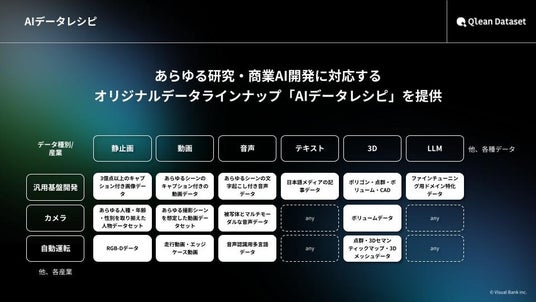
『Qlean Dataset』の提供するデータセットの特徴
- 研究開発、商用利用に対応
Qlean Datasetの提供するデータセットは、データ取得およびAI開発への利用に関する同意書を「すべての被写体」から取得しており、各国のプライバシーポリシー等にも対応しているため安心して研究・商用利用いただくことが可能です。
- 「AIデータレシピ」からデータセットを提供するため、スピーディーかつROIを最大化
AIデータレシピというQlean Dataset独自の提供形態を取ることにより、初期投資を抑えたデータ調達を行っていただくことが可能です。
- 「AIデータレシピ」のラインナップにないデータセットは、個別要件に従った作成・構築も可能
独自性の高いデータについても『Qlean Dataset』のケイパビリティを活用し、個別最適化された要件のデータセットをご提供可能です。
Qlean Dataset お問い合わせフォーム:https://qleandataset.visual-bank.co.jp/contact
Qlean Dataset サービスサイトURL:https://qleandataset.visual-bank.co.jp/
ともに、AI開発を支えるデータパートナーを募集
Visual Bankでは、AI開発を支える多様なデータ提供体制を強化するため、音声・画像・動画・3Dなどの各領域でデータパートナーシップの拡大を進めています。
Qlean Datasetは、信頼できるパートナーとの連携を通じて、AI時代に対応した知的財産保護とデータの価値最大化の両立を目指しています。
研究機関・企業・クリエイターの皆様と共に、安心してデータを活用できる環境を築いてまいります。
Qlean Dataset パートナー詳細URL:https://qleandataset.visual-bank.co.jp/partner
Qlean Dataset パートナーお問い合わせ:https://qleandataset.visual-bank.co.jp/contact-partner
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL: https://amanaimages.com/about/
【Translation】
Qlean Dataset Releases Japanese Two-Person Business Dialogue Corpus for Conversational AI and Speech Recognition
Comprehensive speech and text dataset designed for ASR, LLM, and CX model development
[画像7: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-223485b6da1b0ea8c928ccba6e5906c2-1200x630.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
Visual Bank Inc. (Tokyo, Japan; CEO Saneyuki Nagai) has announced the release of the “Japanese Two-Person Business Dialogue Speech Corpus and Text Dataset” through its AI training data solution, Qlean Dataset, developed under its subsidiary Amana Images Inc. The dataset contains hundreds of hours of natural Japanese two-person dialogues with transcriptions, speaker labels, and timestamps for AI applications such as ASR, conversation understanding, and text summarization.
It can be used for both research and commercial purposes to advance Japanese speech corpus accuracy, CX analysis AI, and conversational LLM training.
▶ AI Data Recipe: https://qleandataset.visual-bank.co.jp/en/lineup
▶ About Qlean Dataset: https://qleandataset.visual-bank.co.jp/en
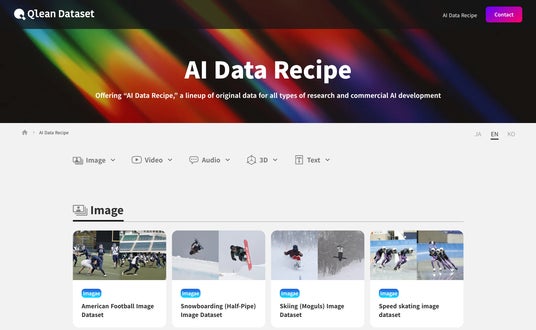
About the “AI Data Recipe” of Qlean Dataset
The "AI Data Recipe" within Qlean Dataset represent its commercially available lineup of original datasets.
They are designed for flexible combination based on usage, accuracy, and delivery requirements, and include both annotated and non-annotated data. Each dataset can be customized or expanded to meet specific needs.
Through partnerships with organizations such as Chiba Lotte Marines and Toyo Keizai Inc., as well as domestic and international networks and new recording projects, Qlean Dataset continues to expand its lineup.
This approach significantly reduces the workload required for data collection and preparation in AI development and accelerates project execution.
[画像8: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-a36bbba405d31979c85847ba2e0996d0-2964x1824.png?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像9: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-b7e20f9a87390854c8889962c6bd8799-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像10: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-8c757599a91e872556f8e644902016f3-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
[画像11: https://prcdn.freetls.fastly.net/release_image/108024/95/108024-95-ca73ca9a4c9ef8166bd095a3f8ac04bc-960x540.jpg?width=536&quality=85%2C75&format=jpeg&auto=webp&fit=bounds&bg-color=fff ]
Overview of the Newly Released Dataset
- Data Types: Audio, Text
- Subjects: Japanese male and female speakers
- Formats: Audio (wav), Text (txt)
- Recording Length: Hundreds of hours
- Scenes: Business meetings, SaaS inquiries, outbound calls, and other professional interactions
- Transcription Structure: Line number, start time, end time, speaker label, utterance content
- Sample Details:https://qleandataset.visual-bank.co.jp/lineup/pn-013
Use Case Examples of the Dataset
- Enhancing ASR and Speaker Diarization ModelsCollected across multiple environments (including online and face-to-face dialogues), the data supports robust speech recognition and speaker separation research, including overlapping speech handling and noise resilience.
- Training for Conversation Understanding and Summarization AIPrecise transcriptions with timestamps and speaker segmentation enable development of models for long-form conversation summarization and next-utterance prediction.
- CX and Emotional Speech Recognition AIIncorporating emotional nuances such as tone and pauses, the dataset is ideal for customer satisfaction analysis and automated call quality evaluation AI.
- Sales Intelligence and Negotiation AnalysisCovers practical dialogues from sales meetings and interviews, supporting AI that quantifies listening skills and conversation patterns.
- Contact Center Automation and FAQ Generation AIIncludes authentic customer support interactions, useful for training voice bots and FAQ generation models.
- Speech UX and Conversational Interface DesignNatural tempo and response patterns make it ideal for training AI assistants and smart-speaker voice UX systems.
- Emotional Change Detection and Experience Quality EvaluationSupports AI research on emotion detection and experience quality assessment through pitch and pause analysis.
- Japanese LLM and Multimodal Generative AI TrainingThe paired speech-text structure enables multimodal LLM development and Japanese dialogue generation research.
Features of Qlean Dataset
All datasets are rights-cleared and commercially usable, collected with full participant consent and international privacy compliance.
Delivered via flexible “Data Recipes” for rapid deployment and customizable dataset creation.
Contact form: https://qleandataset.visual-bank.co.jp/en/contact
Service site: https://qleandataset.visual-bank.co.jp/en
About Visual Bank Inc.
Visual Bank Inc. is a next-generation data infrastructure company committed to “unleashing the potential of all data.”
The company operates THE PEN, an AI-powered assistance tool for manga artists, and wholly owns Amana Images Inc., which provides the AI training data service Qlean Dataset.
Visual Bank has been recognized in national R&D programs and continues to advance initiatives toward real-world AI implementation.
CEO: Saneyuki Nagai
Address: C-Cube Minami Aoyama Bldg. 6F, 7-1-7 Minami Aoyama, Minato-ku, Tokyo 107-0062
Corporate website: https://visual-bank.co.jp/en/
Amana Images overview: https://qleandataset.visual-bank.co.jp/en/company-overview






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}